4.5 超並列知識ベース
プログラムの超並列処理を行う2分木ポリプロセッサはプログラムを読み込み、解析結果の内部状態を各プロセッサの局所RAMのブログラムカウンタの位置に格納する際に、変数名をコードに変換して格納し、変数名とその値及びコードの対応表を作らなければならない。プログラムの実行時には、常時対応表を検索し、伝播してくる変数名と値の順序対に一致する変数名がある場合には値を更新しなければならない。これらの処理は変数名が非常に多い場合には相当の時間を必要とする。この変数名の検索を2分木ポリプロセッサで超高速処理することができる。この2分木ポリプロセッサは超並列2分木データベースの原理を与える。
図5.18にその概略構造を示す。根のプロセッサaのポート2に接続するプロセッサをbとし、同様に、順次にポート2に接続するプロセッサをc, d,・・・・・とする。これらの接続方向に垂直な面においてaのポート1に接続する2分木ポリプロセッサを構成し、同様に、b, c, d,・・・・・のボート1にもこれと合同な2分木ポリプロセッサを接続する。これらをa層、b層、・・・・・の2分木ポリプロセッサと呼ぶ。これらの2分木ポリプロセッサを構成する各プロセッサには入出力ポート4, 5を設け、入出力ポート4を前の層のポート5に接続することにより、各層の同じ位置にあるプロセッサを串刺し状に接続する。入出力ポート4, 5は真と偽を送受信できればよい。
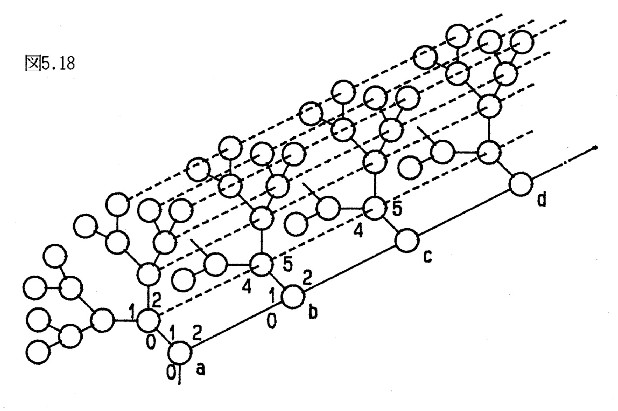
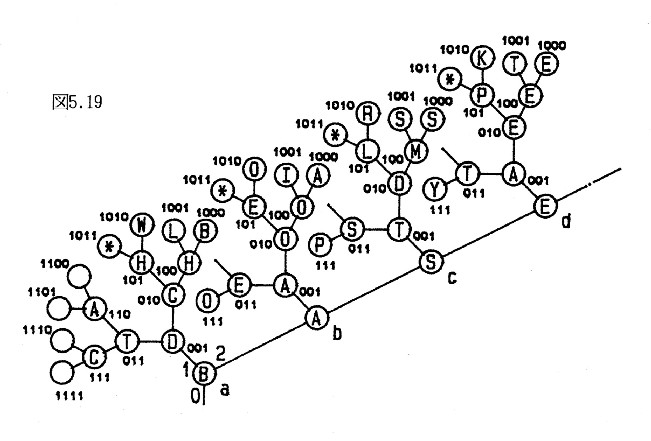
変数名を表す文字列は第1文字から順番にポート4,5により串刺し状に接続された各層のプロセッサの内部状態に格納される。その格納状態を図5.19に示す。各層の同じ2進コードを付けたプロセッサが1個の文字列を表す。001のプロセッサはDATAを表し、1010のプロセッサはWORKを表している。図では文字列は4文字であるが、文字数は任意であり、短い文字列は後ろの層のプロセッサには空白が入れられる。各プロセッサにはアドレスはなく、図の2進コードは内部状態と同じ文字をポート0に受けたときポート0に返すコードであり、文字列の追加のあるとき決められる。
プロセッサaのポート0に文字列BASEが入力されたとき、最初の文字を内部状態として残りの文字列をポート2に出力する。プロセッサb, c, dも同様にして順番に1文字を内部状態とする。内部状態が確定したプロセッサはそれをポート1に出力してコードの返送を待つ。ポート1に接続された2分木ポリプロセッサの各プロセッサが次の動作規則を実行することにより、文字の伝播と検索が行われる。
[ポート4,5を用いない場合の検索動作規則] (空白は文字、空は何も無い。)
| ① | 内部状態が空でないなら、ポート0に受けた文字をポート1と2へ出力して内部状態と比較し、一致すればポート0へ自分のコードを返す。 |
| ② | 内部状態が空なら、ボート0の文字を内部状態とし、自分のコードに文字列追加の確認を求める印を付けてポート0に出力し、文字列追加動作⑦に入る。 |
| ③ | 比較を終えたプロセッサはポート1と2にコードを返されたなら小さいコードを先にポート0へ転送する。両ポートの最後の入力は追加確認の印の付いたコードであり、小さいコードをポート0へ転送し、大きいコードのポートには不許可を返す。 |
| ④ | プロセッサa, b, c,・・・の検索文字列最後の文字を内部状態とするプロセッサはポート1のコードを全てポート0へ転送し、ポート0に文字列追加の許可、不許可を返されたらポート1と2へ転送する。 |
| ⑤ | 最後の文字を内部状態とするプロセッサ以外はポート1と2に受けたコードが一致するものをポート0へ転送する。追加確認の処理は④と同じ。 |
| ⑥ | プロセッサaはポート0へ転送したコードが追加確認印の付いたものであるときは許可を、そうでないときは不許可をポート1と2へ返す。不許可を返したときは追加確認印の付いたコードは捨てる。 |
| ⑦ | 文字列追加の確認を求めたプロセッサはポート0に不許可を受けたなら内部状態を空にし、許可を受けたなら内部状態を確定して(自分のコード)×2+(1 AND ポート番号)のコードをポート1と2へ出力する。その他のプロセッサはポート0に受けた許可、不許可をポート1と2へ転送する。 |
| ⑧ | 追加を行ったプロセッサのポート1と2に接続するプロセッサは、内部状態が空ならポート0に受けたコードを局所RAMに格納する。 |
図5.19の場合は、追加確認を求めるのは外周にある1011~1111及び図に表記を省略した10000~10101のプロセッサで、最小のコード1011がプロセッサa, b, c,・・・ に到達する。この他にプロセッサaは1000を、bは0001, 1000を、cは0011, 1000, 1001を、dは0010, 0100, 1000を受け取り、プロセッサaは全てに共通の1000をポート0へ出力して追加確認に不許可を与える。検索文字列がCASEであると共通のコードは追加確認印の付いた1011だけであるのでこれをボート0へ出力して追加の許可を与える。許可は全てのプロセッサに伝播し、許可を求めたプロセッサが内部状態を確定して新しい文字列CASEが記憶される。
文字列HOMEを削除するときは検索と同様の動作により、各層の削除文字と同じ内部状態のプロセッサが確認を求める印を付けてコードをポート0に送り出し、プロセッ サaはa, b, c, dに共通の0100を送り返す。このコードは全てのプロセッサに伝播し、削除確認を求めたプロセッサの内コードの一致する0100のプロセッサは内部状態を空にする。その後の検索ではこのプロセッサは文字列追加の確認を求める動作を行い、確認を求める最小のコードを持つので新しい文字列はここに格納される。
アルファベットの大文字と小文字及び数字を合わせると62文字であるから、文字列の総数が65535個であると、各層の2分木には平均1057個の同じ文字があり、これが各層の根のプロセッサに集中する。65535=216-1 であるから、平均1057個の各層の候補を選出する所要時間は直列に接続された16個のプロセッサが1個の文字を順に送って比較検査するに要する時間であり、検索所要時間は平均1057個の候補コードから1個を選出する時間で決まる。これでも相当な検索の高速化が達成されるが、候補の選出時間に比べ、候補から1個を選出するのに桁違いの時間がかかる。これを解決するために入出力ポート4と5が設けられている。
このときの動作規則は次頁に示す。入出力ポート4と5により検索文字列の全文字の一致を調べることにより、プロセッサaは唯一つのコードを受け取り、ポート0へ転送する。そのコードに追加確認を求める印がある場合はポート1と2へ許可を送る。文字列削除の場合は動作規則②において真をポート5へ送ったプロセッサは内部状態を空にする。これらの検索所要時間は65535個の文字列がある場合に、直列に接続された16個のプロセッサが1個の文字を順に送って比較検査するに要する時間である。
[ポート4,5を用いる検索動作規則]
| ① | 内部状態が空でないなら、ポート0に受けた文字をポート1と2へ出力して内部状態と比較し、不一致ならポート4と5へ偽を出力して比較処理を終える。 |
| ② | 一致すれば、a層のプロセッサはポート5に真を受けたならポート5へ返送し、他のプロセッサはポート5の真偽をポート4へ、ポート4の真偽をポート5へ転送する。偽を転送したときは比較結果を偽に変えて比較処理を終える。ポート5に真を転送したときはポート0へ自分のコードを出力し、ポート1と2へ追加不許可を送る。 |
| ③ | 内部状態にある文字列と検索文字列の最後の文字の後ろには空白文字があり、両方の空白文字が一致したプロセッサはポート4へ真を出力する。 |
| ④ | 内部状態が空なら、ポート0の文字を内部状態とし、自分のコードに文字列追加の確認を求める印を付けてポート0に出力し、文字列追加動作⑦に入る。 |
| ⑤ | 削除により内部状態が空の場合は、ポート1と2に追加確認印の付いたコードを受けてから両ポートに不許可を出した後、④の動作を行う。一方が検索されたコードのときはポート0へ転送し、他方に不許可を出して自分の内部状態も空に戻す。 |
| ⑥ | 比較を終えたプロセッサはポート1と2に追加確認の印の付いたコードを受けたときは小さい方をポート0へ転送し、大きいコードのポートには不許可を返す。一方が検索されたコードのときはポート0へ転送し、他方に不許可を出す。 |
| ⑦ | 文字列追加の確認を求めたプロセッサはポート0に不許可を受けたなら内部状態を空にし、許可を受けたなら内部状態を確定して(自分のコード)×2+(1 AND ポート番号)のコードをポート1と2へ出力する。その他のプロセッサはポート0に受けた許可、不許可をポート1と2へ転送する。 |
| ⑧ | 追加を行ったプロセッサのポート1と2に接続するプロセッサは、内部状態が空ならポート0に受けたコードを局所RAMに格納する。 |
この方法は、a層の2分木だけで構成され、文字列を各プロセッサの局所RAMに格納するシステムで、先頭文字の一致したプロセッサが逐次に後続の文字の一致を調べる操作をb層以降の2分木を用いて並列処理に変えたものである。従って、b層以降の2分木は検索結果のコードの転送や追加確認の許可、不許可の転送を行うことは必要ではない。追加の確認に対して許可を受けたa層のプロセッサがポート5へ真を送ることで文字列追加を行うことができる。このとき、b層以降のプロセッサは変数の値やその他の属性を出力するように変更することができる。
この検索2分木ポリプロセッサはプログラムを処理する2分木ポリプロセッサの局所RAMにある変数表を2分木ポリプロセッサに替えたものであるから、プログラムを処理する2分木ポリプロセッサの各プロセッサに入出力ポート3を設けて検索2分木のプロセッサaのポート0を接続する。しかし、これは相当膨大なポリプロセッサとなる。規模縮小のために、ブログラムを処理する2分木の外部に検索2分木を1個設け、検索速度の超高速性を利用して変数を集中管理することができる。このとき、これを利用して各種の興味ある情報処理を行うことができる。
図5.19において、検索文字として先頭の3文字は任意で4番目がEであると指定する。従って、a, b, c層の各プロセッサは比較を行わずに、比較が一致したとして処理を行う。このとき、プロセッサaは0010, 0100, 1000のコードを受けるのでこれらのコードをa層のプロセッサに順に伝播させてコードに対応する文字列の出力を要求する。プロセッサa, b, c, dはCODE, HOME, BASEの文字列を受け取り、外部に出力する。同様にして、4番目の文字の同じ文字列をグループにして外部に出力することができる。これは分類と言われる。分類とはポリプロセッサの外部に文字列をグループ分けする処理であり、内部では文字列は分類されていない。
文字列CASEの検索を求めたとき、図5.19ではこの文字列は記憶にないのでプロセッサaがa層のプロセッサの比較結果を一致と見做して処理する指令を出すとBASEが出力される。これは連想と言われる。プロセッサa, b, c, dが後入優先で内部状態を確定すると、検索文字列は逆順にESACとセットされ、この文字列が記憶にあれば出力される。これも連想である。分類という処理も連想により行われている。従来、連想は記憶の仕方に依存するとされ、連想可能な方式を連想記憶というが、ポリプロセッサでは記憶された文字列には連想のための処理は何ら施されておらず、検索の際の条件の指定により連想が行われる。従って、ポリプロセッサでは連想記憶ではなく、連想検索と言わなければならない。
図5.19の文字列を構成する各文字が項目の内容を表しているとすれば、文字列はそれらの項目からなるレコードを表す。a層の文字が氏名、b層の文字が生年月日、c層の文字が住所、等々の一般的データを表すなら超並列データベースである。この超並列データベースでは、管理プログラムとデータベースは一体構造であり、データは管理プログラムの働きをする2分木ポリプロセッサの局所RAMに項目毎に分散記憶される点で従来のデータベースの概念とは著しく異なる。
a層の文字は漢字の音読み、b層の文字は訓読み、c層以降の文字は意味や文法的な属性を表すなら漢字辞書である。この辞書は意味からも引くことができる。後方の層のプロセッサには文字のドットパターンをバイト単位等により格納しておけば文字パターンから辞書を引くことができる。文字パターンを構成する各バイトのドットパターンは図5.19の1文字に相当し、文字パターンは文字列に相当するから、この比較は並列に超高速で行うことができる。手書きの文字の場合は完全に一致することはないので、一致の程度を表す適当な評価関数を導入する。一般のパターン認識も図5.19の1文字がパターンの特徴パラメータを表すものとすれば、文字列の認識と同様に超高速な並列パターン認識が行える。
従来、データベースと知識ベースは区別されるが、ポリプロセッサの超並列データベースと超並列知識ベースには区別はない。知識データの定義を命題のような論理学の形式で記述されたものと限定するなら取り扱うデータに違いがあると言うことはできる。しかし、住所録も「何某は何年何月何日に生まれた」「何某は何処々々に住んでいる」という知識に関する命題を集めたものと考えることができる。辞書も命題の集まりであり、文字パターンも述語の集まりである。知識ベースは推論機構と組みであるとも言われる。しかし、ポリプロセッサの推論は文字列の検索で述べた連想検索という手法により行われ、超並列データベースも推論機構を備えている。正確には、推論機構を構成する2分木ポリプロセッサの各局所RAMにデータベース又は知識ベースが分散構成されているのである。
図5.19の入出力ポート4と5で結合されたプロセッサを行プロセッサと呼び、その内部状態で構成される文字列を真なる命題の集まりと考える。010の行プロセッサの内部状態は「CはOである」「CはDである」「CはEである」という命題の集まりである。即ち、a層のプロセッサの内部状態は対象であり、b層以降のプロセッサの内部状態はその対象に対する述語である。命題「CはEである」の真偽を問う場合は、プロセッサaはCを検索し、プロセッサb, c,・・・は全てEを検索する。文字列の検索と動作規則の異なる点は、追加の処理を行わない他、次の通りである。
[命題の真偽の計算動作規則]
| ① | b層以降のプロセッサは内部状態との比較が不一致ならポート5の真偽をポート4へ転送し、ポート4の真偽をポート5へ転送して終了する。 |
| ② | 比較が一致すればポート4へ真を出力し、ポート4に偽を受けたら終了する。真を受けたならポート0へ内部状態の複写を出力して終了する。各行プロセッサの内部状態が空のプロセッサはポート4へ偽を出力して終了する。 |
| ③ | a層のプロセッサは内部状態との比較が一致すればポート5の真偽をポート5と0へ出力する。比較が不一致ならポート5の真偽に偽を返送し、ポート5が真のときは内部状態の複写をポート0へ出力してこの対象に対する処理を終了する。 |
| ④ | プロセッサaはポート1に真を受けたらポート0へ転送して終了する。偽を受けたときは、ポート1に対象を受けた場合はポート2へ転送し、全プロセッサは①から繰り返す。ポート1に対象を受けない場合は偽をポート0へ出力する。 |
| ⑤ | 各層外周の内部状態が空のプロセッサはポート0へ終了記号を出力し、終了記号をポート1と2に受けたプロセッサはポート0に1個だけ転送する。 |
命題「CはEである」の場合はa層とd層の010のプロセッサが内部状態との一致を検出するのでこの命題は真である。このとき、Eを述語に持つ対象B, Hは内部状態非破壊で出力されるが、プロセッサaはこれを無視する。命題「CはSである」の場合は同じ命題が存在しないのでプロセッサaは偽を受けるが、対象T, B, Lを受けるので次々と連続的にT, B, Lをポート2へ転送し、これらを述語とし、与えられた命題と同じ対象の命題「CはTである」「CはBである」「CはLである」の真偽を調べる。いづれも偽が報告され、これ等を述語に持つ対象D, Hが報告される。再度D, Hをポー ト2へ転送し、「CはDである」「CはHである」の真偽を求めると010のプロセッサが真を報告する。故に、「CはSである」は真である。
このとき、真と判定するに至った命題の関係が必要な場合は、プロセッサaはこのとき真であった命題「CはDである」を、プロセッサcがポート1に受けてポート0へ転送する述語Dをボート2に受けることにより知ることができる。そこで、命題「DはSである」の真偽を問うと、同様に、「DはTである」により真であることが分かる。更に、命題「TはSである」の真偽を問うと、この命題「TはSである」が真であることを知る。故に、四段で「CはSである」という結論に達することが分かる。途中の「DはTである」「TはSである」の命題を一つにまとめれば三段論法「CはDである」「DはSである」故に「CはSである」が導かれる。
即ち、三段論法は推論の手段ではなく、推論の過程にある命題を最終到達命題から逆方向に示して推論の正しさを明確に表現する一つの手段である。推論は結論から大前提を導く方向に行われなければならない。大前提から結論へと推論を行うと、対象Cの述語の全てについて、それが対象である命題の全てを調べ、それらの述語について、それが対象である命題の全てを調べるというように探索の範囲が末広がりに拡大し、超並列処理でも、上記の三段論法を見出すよりも遥かに時間を必要とする。
2分木ポリプロセッサにおける文字列の検索は与えられた命題の順序対と記憶されている命題の順序対とのAND計算に相当し、要素毎のANDが全て真のとき真である。少なくとも1要素のANDが真の場合を連想という。命題の真偽の計算は行プロセッサで表される命題集合と与えられた命題1個の命題集合とのAND計算であり、この命題の検索である。同じ命題がなくても、三段論法により命題があるのと等価であるなら真であり、これも連想である。連想は結論を導く処理であり、逆に、結論の原因となる多段論法の出発命題を求める処理が推論である。人間は多段論法を行うとき、結論を常に念頭において目標から外れないように命題を選んで行く。これは、ポリプロセッサと同様に結論から逆に出発命題を求め、その述語を対象とする結論から逆に出発命題を求める処理を繰り返して命題を連結して行くことを示している。
述語は対象を変数に代入すると値の確定する関数であり、多段論法は、この述語を対象として次々と関数を計算するのであるから、微係数を次々と積分して関数またはアナログ現象を再現する合成に相当する。連想は少々の違いは無視して同じと見做す処理であり、これも細かな変動を平滑化する積分に相当する。推論は、三段論法という命題の連結による結論の命題の合成に必要な各命題を求める処理であり、積分による関数の合成に必要な各微係数を求める微分解析に相当する。その手続きは、述語という関数から対象を求める計算であり、逆関数の計算である。
命題計算「CはDである」⇒「TはSである」は三段論法を導いた過程から真である。しかし、命題計算は命題の内容には立ち入らないのであるから両方の命題が推論の過程に存在する必要はない。従って、単純に「CはDである」の真偽を調べ、それが偽なら「CはDである」⇒「TはSである」は真であり、前提が真なら結論の真偽に同じである。論理和、論理積も同様に命題の真偽の推論で処理される。