4.2 自然言語によるプログラム
アセンブラは英語命令文で記述されるが、これを日本語で、「aにbを加えよ/aにcを掛けよ/aが負ならL行へ行け/・・・」と命令文で記述すると奇異な感じを受ける。英語の命令文はGodの命令であり、それが普通であるが、日本語では命令文だけを羅列するのは普通ではないのである。実際に、我々がアセンブラのプログラムを読むとき命令を受けているという感じは持たない。主語がなくて普通であるという日本語的感覚で読むからである。しかし、日本語命令文に直して読むと自分が命令されている感じを受ける。英語は命令形が基本形であるが日本語は叙述文が基本形であるからプログラムは叙述文で記述し、「aにbを加える/aにcを掛ける/aが負ならL行へ行く/・・・」とすれば普通になる。BASICの入出力文も「xを入力(する)/yを印刷(する)」とすればよい。OSのプロンプト文で「・・・してください」を連発するのも英語でPleaseを連発するようなもので奇異である。
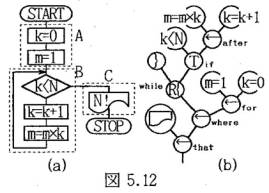 N!を求めるプログラムは図5.12(a)のフローチャートで表され、点線枠で示す3つの処理A,B,Cの逐次処理であるから図5.7(本HPの3.4節Fig3.9参照)のⅠ型の2分木に変換でき、更に、AはⅠ型、BはⅢ型であるから図5.12(b)の2分木に変換できる。但し、A,B,Cの逐次処理を示す演算子は2重目的語を持つ動詞と同じ作用方向とし、プログラムの2分木と逆であるので矢印でそれを示している。A,B,Cの順序も逆でCが根側になっている。又、代入文や関係式の2分木表記は省略している。
N!を求めるプログラムは図5.12(a)のフローチャートで表され、点線枠で示す3つの処理A,B,Cの逐次処理であるから図5.7(本HPの3.4節Fig3.9参照)のⅠ型の2分木に変換でき、更に、AはⅠ型、BはⅢ型であるから図5.12(b)の2分木に変換できる。但し、A,B,Cの逐次処理を示す演算子は2重目的語を持つ動詞と同じ作用方向とし、プログラムの2分木と逆であるので矢印でそれを示している。A,B,Cの順序も逆でCが根側になっている。又、代入文や関係式の2分木表記は省略している。
図5.12(b)から文結合演算子の作用方向に従って出力すれば(a)のフローチャートが得られるが、文結合演算子を日本語にすれば次の文が得られる。
英語でも日本語を直訳した形式に記述することはできるが、結論を先に述べ、それ に到る過程、理由や条件は関係詞や前置詞を用いて後に続けるのが普通である。実際に、英語が日本語と記述の順序が逆であることが同時通訳を困難にしている。テレビの同時通訳はしどろもどろの日本語にしか聞こえない。最後まで聞いて前後を逆に訳さなければ普通の日本語にならないのである。同様に、頭から直訳して普通の日本語になる英語は欧米人にはあまり良い英語ではないのである。従って、同図(b)の英語表記は2分木の根より葉に向かって、次の様に記述される。
N!の定義は「Nから1迄の整数の積、但し、0!=1」であり、“N!=N×(N-1)×・・・×1, 0!=1”と数式で記述できる。この数式は×演算子を先入優先で2分木ポリプロセッサに入力すれば2分木に変換できる。この2分木は(N-1)以降の2分木を処理結果に置き換えれば簡単に“N!=N(N-1)!, 0!=1”の2分木で表せるが、この数式表現には右辺の(N-1)!は同じ2分木で(N-1)!=(N-1)(N-2)!として得るという繰返処理の意味が含まれているので、それを2分木に表すと図5.12(b)の2分木が得られる。これを自然言語で表せば上の日本語や英語による記述が得られる。同図(a)のフローチャートは2分木の節である演算子を図形とそれを結ぶ線で表すことにより得られる。
N!の定義の数式による記述及び日本語文や英文による記述及びフローチャートはア ルゴリズムといわれるが、BASICによる記述はプログラムと言われる。しかし、これらは図5.12(b)の2分木で表され、本質的な違いはない。現在のコンピュータにはプログラムは理解できるが、定義やアルゴリズムは理解できないという違いがあるだけである。自然言語の構文が2分木構造であり、人間の脳が2分木解析を行っていると考え、それを模擬したポリプロセッサではこの違いは解消され、数式と自然言語により記述されたアルゴリズムはプログラムである。
従来、自然言語の処理は数値計算プログラムの処理と同様に行われ、主記憶装置にある解析プログラムによりデコーダが主記憶装置にある自然言語文の構成要素を演算装置に送り込んで処理する。一方、2分木ポリプロセッサでは自身が解析装置であり主記憶装置はなく、文は単語単位で各プロセッサの局所RAMの文番号または行番号カウンタの示す位置に分散記憶される。英語を日本語に翻訳出力する場合には、カウンタの示す局所RAMの内容を内部状態に読み出し、日本語に変換し、各プロセッサは日本語出力規則に従ってポート1の入力、ポート2の入力、内部状態をポート0に出力する。このようにして翻訳等の自然言語の超並列処理が行われる。